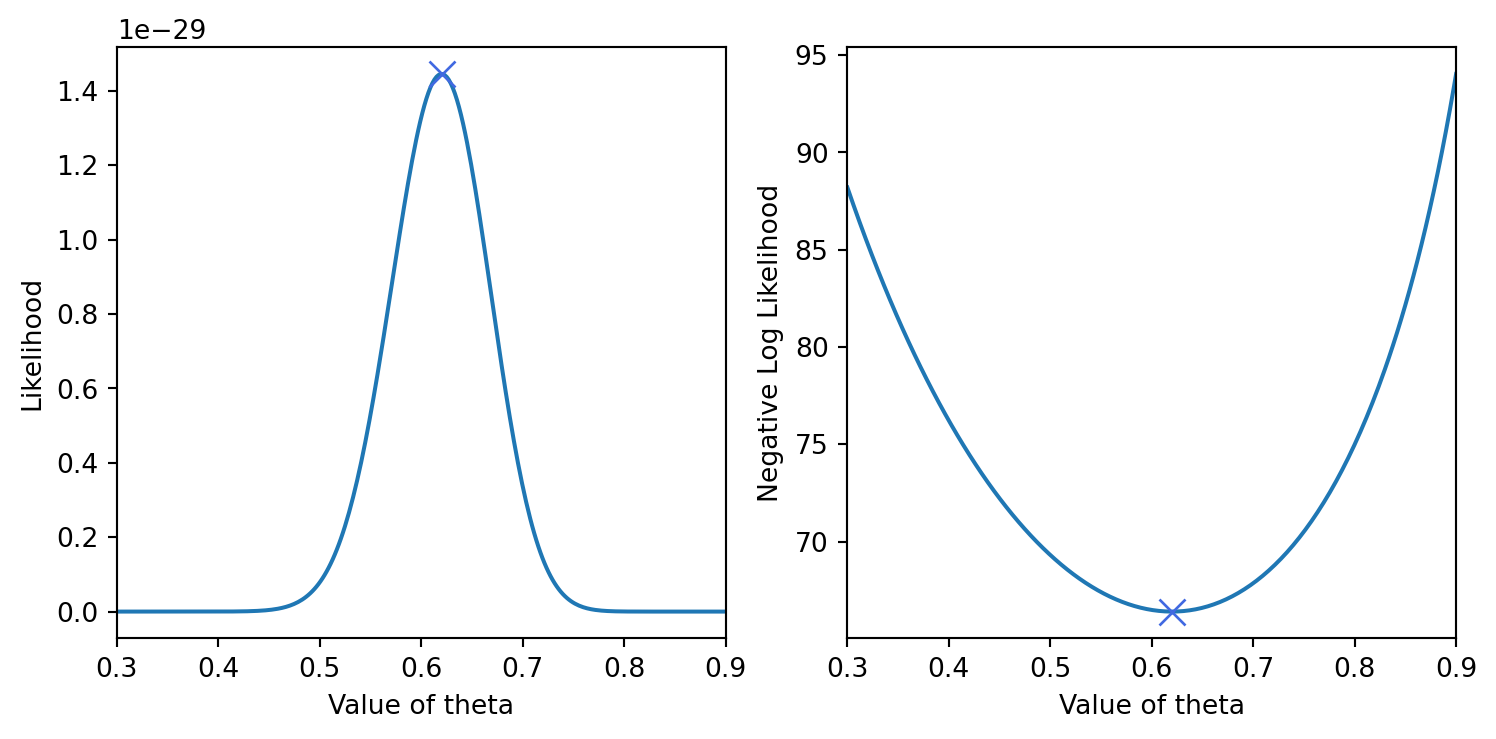
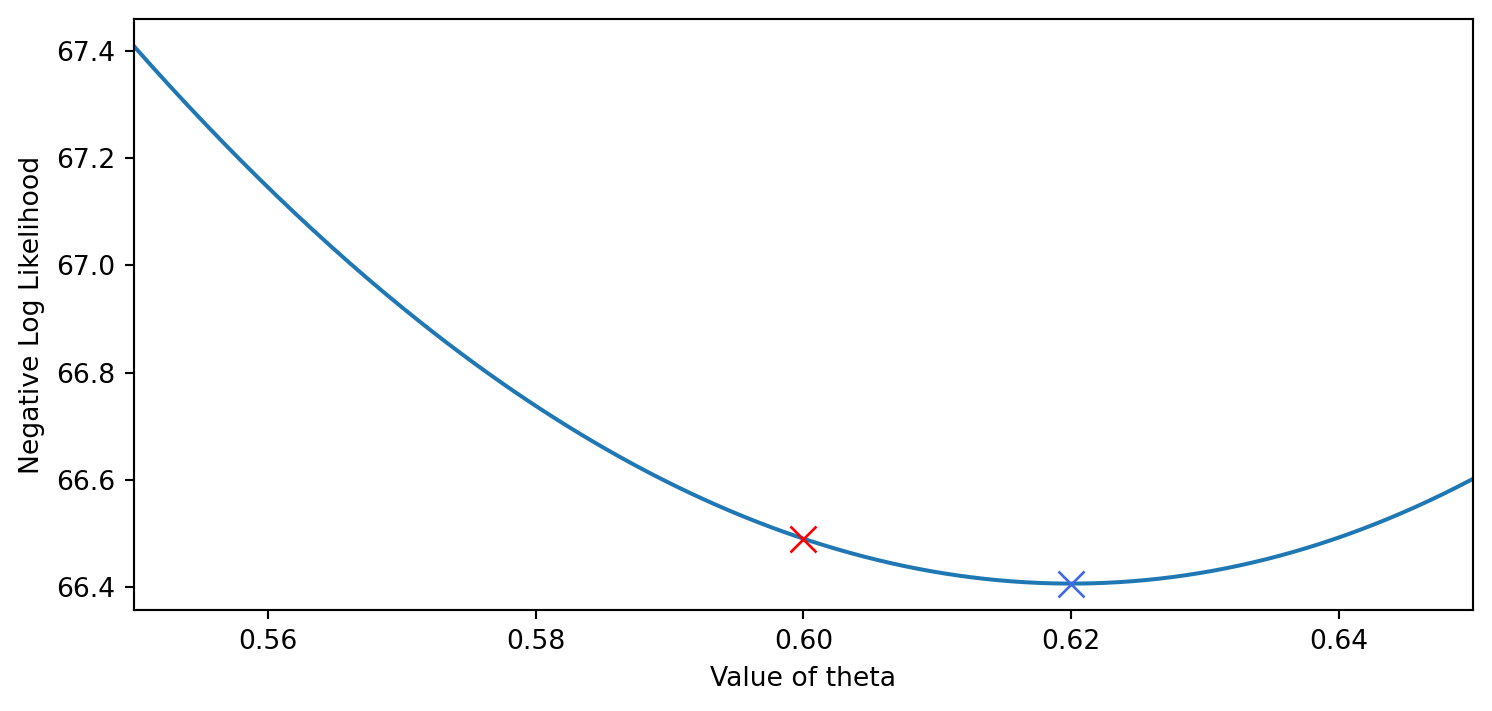
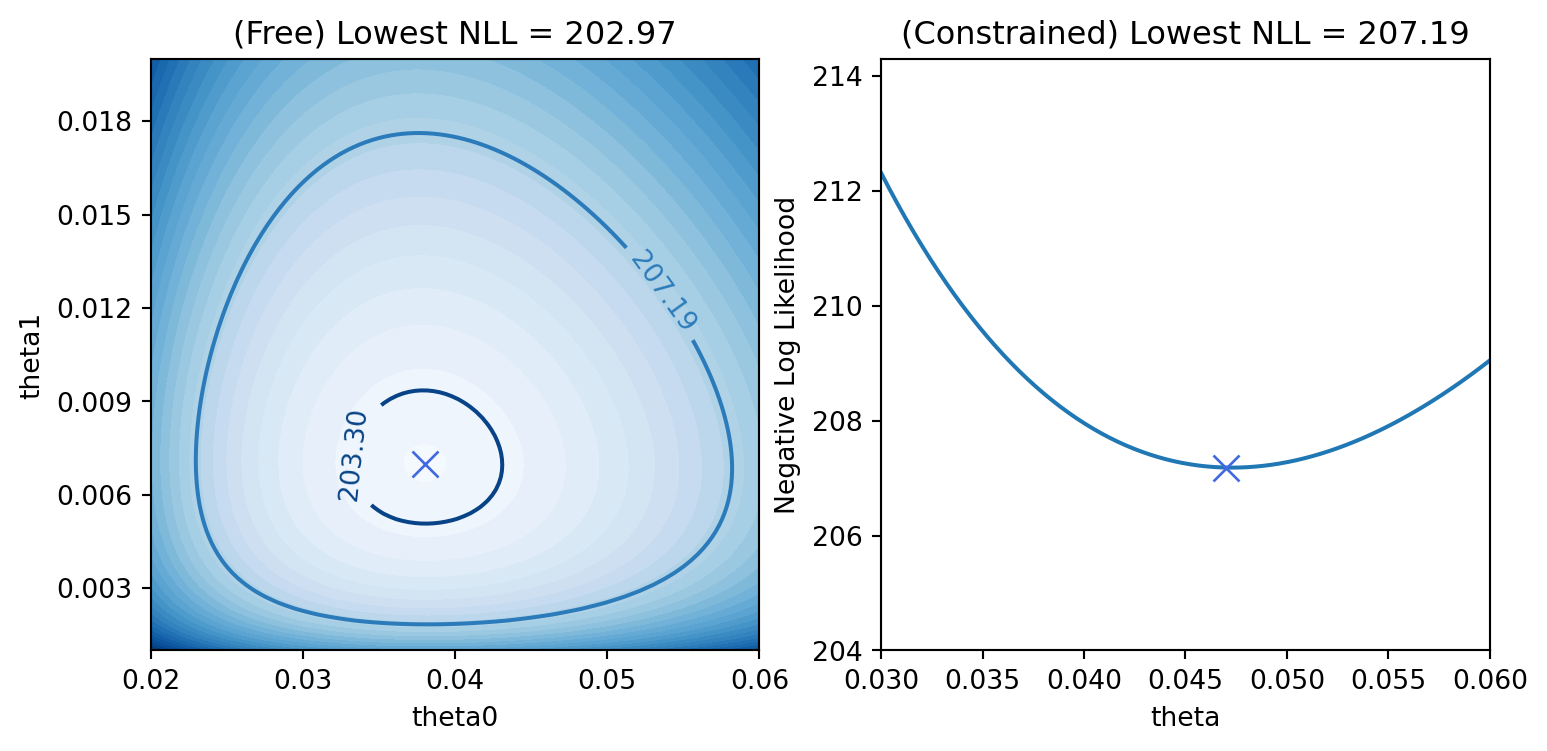
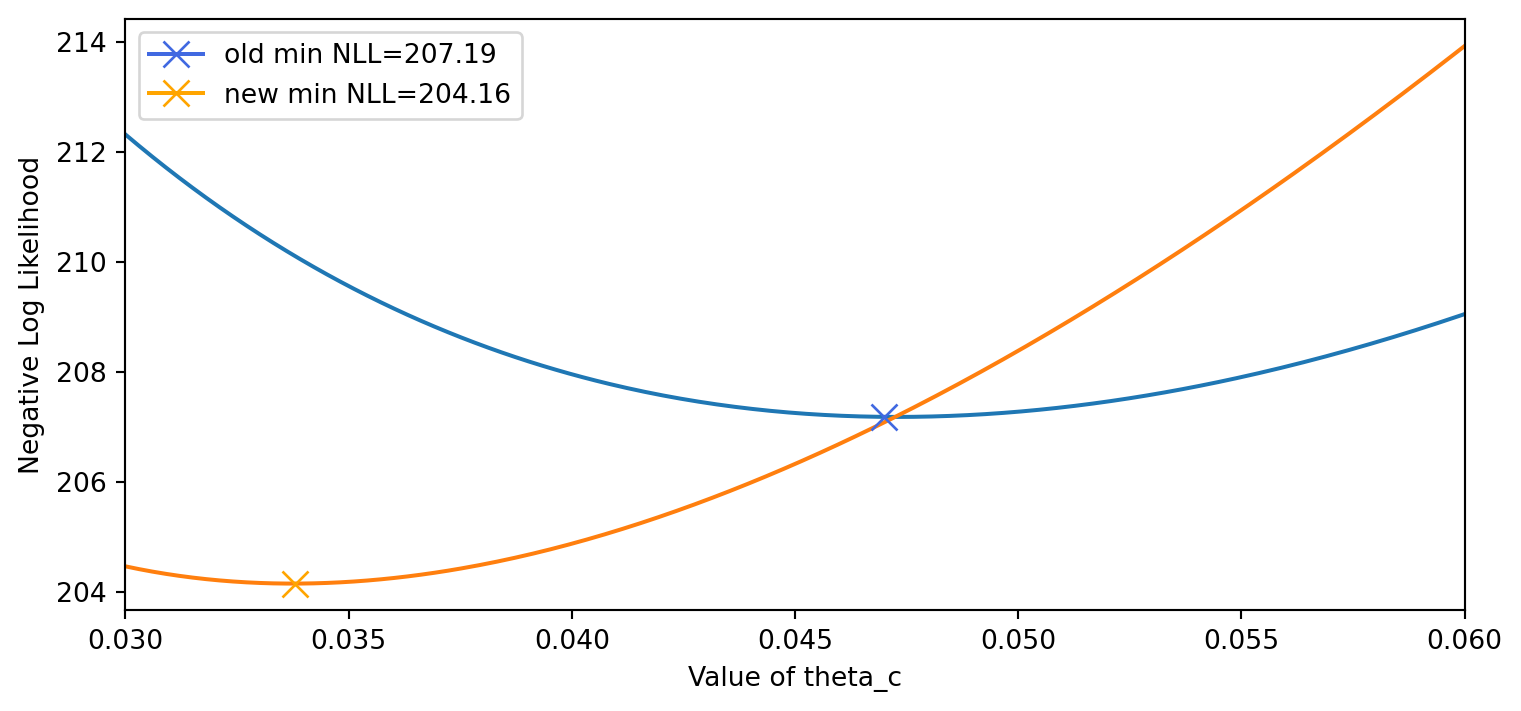
Anderson, P. W. (1972). More is different.
Science,
177(4047), 393–396.
https://doi.org/10.1126/science.177.4047.393
Bavarian, M., Jun, H., Tezak, N., Schulman, J., McLeavey, C., Tworek, J., & Chen, M. (2022).
Efficient training of language models to fill in the middle. arXiv.
https://doi.org/10.48550/ARXIV.2207.14255
Bengio, Y., Ducharme, R., Vincent, P., & Janvin, C. (2003). A neural probabilistic language model. J. Mach. Learn. Res., 3(null), 1137–1155.
Borgeaud, S., Mensch, A., Hoffmann, J., Cai, T., Rutherford, E., Millican, K., Van Den Driessche, G. B., Lespiau, J.-B., Damoc, B., Clark, A., De Las Casas, D., Guy, A., Menick, J., Ring, R., Hennigan, T., Huang, S., Maggiore, L., Jones, C., Cassirer, A., … Sifre, L. (2022). Improving language models by retrieving from trillions of tokens. In K. Chaudhuri, S. Jegelka, L. Song, C. Szepesvari, G. Niu, & S. Sabato (Eds.),
Proceedings of the 39th international conference on machine learning (Vol. 162, pp. 2206–2240). PMLR.
https://proceedings.mlr.press/v162/borgeaud22a.html
Brown, T. B., Mann, B., Ryder, N., Subbiah, M., Kaplan, J., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., Agarwal, S., Herbert-Voss, A., Krueger, G., Henighan, T., Child, R., Ramesh, A., Ziegler, D. M., Wu, J., Winter, C., … Amodei, D. (2020).
Language models are few-shot learners. arXiv.
https://doi.org/10.48550/ARXIV.2005.14165
Chan, S. C. Y., Santoro, A., Lampinen, A. K., Wang, J. X., Singh, A., Richemond, P. H., McClelland, J., & Hill, F. (2022).
Data distributional properties drive emergent in-context learning in transformers. arXiv.
https://doi.org/10.48550/ARXIV.2205.05055
Hornik, K. (1991). Approximation capabilities of multilayer feedforward networks.
Neural Networks,
4(2), 251–257. https://doi.org/
https://doi.org/10.1016/0893-6080(91)90009-T
Izacard, G., Lewis, P., Lomeli, M., Hosseini, L., Petroni, F., Schick, T., Dwivedi-Yu, J., Joulin, A., Riedel, S., & Grave, E. (2022).
Few-shot learning with retrieval augmented language models. arXiv.
https://doi.org/10.48550/ARXIV.2208.03299
Karpathy, A. (2015).
The unreasonable effectiveness of recurrent neural networks.
http://karpathy.github.io/2015/05/21/rnn-effectiveness/
Kudo, T., & Richardson, J. (2018).
Sentence
Piece: A simple and language independent subword tokenizer and detokenizer for neural text processing.
Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, 66–71.
https://doi.org/10.18653/v1/D18-2012
Lazaridou, A., Gribovskaya, E., Stokowiec, W., & Grigorev, N. (2022).
Internet-augmented language models through few-shot prompting for open-domain question answering. arXiv.
https://doi.org/10.48550/ARXIV.2203.05115
Marr, D., & Poggio, T. (1976). From understanding computation to understanding neural circuitry. Massachusetts Institute of Technology.
Meng, K., Bau, D., Andonian, A., & Belinkov, Y. (2022). Locating and editing factual associations in GPT. Advances in Neural Information Processing Systems, 35.
Meng, K., Sen Sharma, A., Andonian, A., Belinkov, Y., & Bau, D. (2022). Mass editing memory in a transformer. arXiv Preprint arXiv:2210.07229.
Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013).
Efficient estimation of word representations in vector space. arXiv.
https://doi.org/10.48550/ARXIV.1301.3781
Min, S., & Xie, S. M. (2022).
How does in-context learning work? A framework for understanding the differences from traditional supervised learning.
http://ai.stanford.edu/blog/understanding-incontext/
Olsson, C., Elhage, N., Nanda, N., Joseph, N., DasSarma, N., Henighan, T., Mann, B., Askell, A., Bai, Y., Chen, A., Conerly, T., Drain, D., Ganguli, D., Hatfield-Dodds, Z., Hernandez, D., Johnston, S., Jones, A., Kernion, J., Lovitt, L., … Olah, C. (2022). In-context learning and induction heads. Transformer Circuits Thread.
Savinov, N., Chung, J., Binkowski, M., Elsen, E., & Oord, A. van den. (2022). Step-unrolled denoising autoencoders for text generation.
International Conference on Learning Representations.
https://openreview.net/forum?id=T0GpzBQ1Fg6
Schunk, D. H. (2011). Learning theories (6th ed.). Pearson.
Strudel, R., Tallec, C., Altché, F., Du, Y., Ganin, Y., Mensch, A., Grathwohl, W., Savinov, N., Dieleman, S., Sifre, L., & Leblond, R. (2022).
Self-conditioned embedding diffusion for text generation. arXiv.
https://doi.org/10.48550/ARXIV.2211.04236
Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, Ł., & Polosukhin, I. (2017). Attention is all you need. In I. Guyon, U. V. Luxburg, S. Bengio, H. Wallach, R. Fergus, S. Vishwanathan, & R. Garnett (Eds.),
Advances in neural information processing systems (Vol. 30). Curran Associates, Inc.
https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf